Как раскрасить HTML таблицу, если надо отмечать разными цветами столбцы (в порядке сортировки) и строки (в зависимости от значений ячеек)? Как обеспечить сортировку и чисел, и строк без явного указания типов? Ответы - в Simple Table Sorter v 0.03.
Простой сортировщик HTML таблиц, версия 0.03
Simple Table Sorter v 0.03
Первый Простой сортировщик HTML таблиц (версия 0), упоминаемый на этом сайте, был придуман далеко не первым по времени, а примерно через год работы над концепцией. Была уверенность, что его невозможно улучшить без громадного скачка в объёме кода (от двух до 15-ти Кб). Но вот накопились (открылись) новые обстоятельства, и мне пришлось изменить своё мнение.
Во-первых, была обнаружена ошибка сортировки одинаковых значений во всех браузерах, кроме Гекко (ФФ). Ошибка была исправлена незначительным изменением алгоритма: при создании массива сортировки к полученному значению стали прибавлять число – порядковый номер в массиве, делённый на одну десятимиллионную (на случай, если само значение будет с десятичными знаками). Ну, если значение окажется не числом, добавятся строки вида "0.000009", "0.000010", всё равно ведь текущее значение будет отличаться от следующего как раз так, как надо.
Хотя на самом деле значение в нашем Простом сортировщике никогда не бывает числом. Все числа перед сортировкой превращаются в строки и впереди добавляются нули, до 10 знаков. Приблизительно так (приблизительно – потому что надо ведь ещё куда-то девать десятичные знаки). Это была ловкая проделка в версии 0 – так организовать сортировку, чтобы можно было обойтись без пользовательской функции. Время работы скрипта, правда, тут не очень заметно экономится, зато кода меньше.
Таким образом, в версии 0 алгоритм преобразования значений для массива сортировки стал таким:
1) Строка превращается в число (parseFloat);
2) Если числа в результате не получилось (isNaN), в массив добавляется исходное значение (например, "Водолей");
3) Если число получилось, оно умножается на 1000 (мы щедро отвели под десятичные знаки аж три позиции) и дополняется впереди нулями до 10 знаков: "99.42" превращается в "0000099420";
4) К полученному значению прибавляется порядковый номер строки в массиве, делённый на какое-то большое число: "Водолей0.000001", "0000099420.000012".
Ну, и тут, кстати, вылезла ещё одна совсем уже смешная проблема. На автомобильном сайте встретились строки, начинающиеся с названия торговой марки "Infinity", и эти строки стали обрабатываться как число, потому что для parseFloat "Infinity" и является числом – "Плюс бесконечнотью"! Пришлось заменить проверку isNaN на isFinite (к счастью, такое чудо в javascript есть).
Во-вторых, по многочисленным пожеланиями пользователей, я пересмотрел концепцию, и увидел, что некоторые улучшения, добавление функций можно сделать и без гигантского скачка в объёме кода. Хотя всё равно в итоге раза в 3-4 код увеличился...
Чего не хватало пользователям
Одно из первых и достаточно очевидных пожеланий – добавить предопределённую сортировку: страница открывается, а таблица на ней уже насортирована по определённым столбцам (именно на стороне клиента). Это логично: раз в скрипте предусмотрена возможность динамического подключения новых таблиц (после загрузки страницы), значит, должен быть и механизм сортировки с помощью задания внешних параметров (сказал "а", надо говорить и "б").
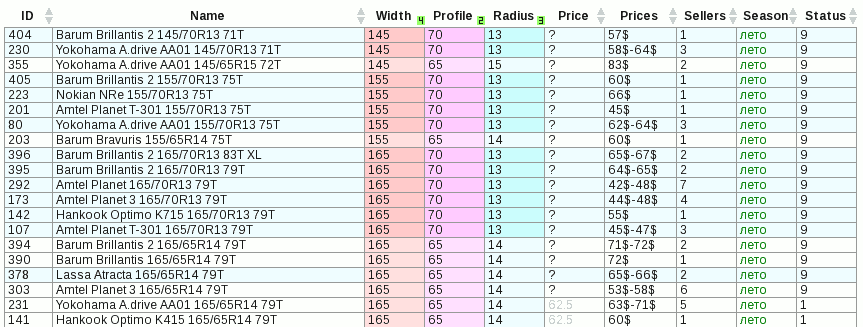
Все последующие изменения предложены веб-разработчиком AleXH и связаны с внешним видом (но они, само собой, повлияли также и на алгоритмы): во-первых, логично подсвечивать не только стрелки сортировки в заголовке, но и полностью столбцы (с помощью изменения фона – чем раньше отсортирован, тем светлее). Во-вторых, возникла интересная идея менять фон строки в зависимости от значений ячеек: если, например, в заранее оговорённых столбцах 2, 3, 4 в текущей строке значения ячеек не отличаются от значений предыдущей строки, фон строк не меняется, иначе он по очереди становится более светлым или более тёмным (отмечаются границы одинаковых диапазонов).
Как всё это удалось реализовать
Самое простое – предопределённая сортировка. Пришлось разделить функцию сортировки на две части: clickTab, sortTab, и тогда вторую часть стало можно вызывать из функции подготовки таблиц, по заданным параметрам, которые хозяин таблицы должен вписать в добавленную в начало скрипта переменную init = {2:desc, 3:asc}, что интерпретируется подготавливающей функцией prepTabs как "сортировать третий столбец по убыванию" и "сортировать четвёртый столбец по возрастанию" (нумерация начинается с нуля). Не очень хорошая идея – влезать каждый раз в текст скрипта для управления содержанием. Позже мы усовершенствуем способ указания параметров.
А пока расскажу, как удалось раскрасить таблицу. Тут легко увидеть назревающий конфликт интересов между раскраской столбцов и строк. Во-первых как вообще можно раскрасить столбцы? Покопавшись в справочниках, мы не обнаружили ничего утешительного: то ли будет работать фон у элемента COL, то ли нет. Пришлось попросту взять и попробовать. Получилось частично: во всех браузерах, кроме IE. В запарке решили забить и сбросить ещё одно очко со счёта уродца. Но потом, когда всё остальное было отлажено, в спокойной обстановке загадку IE тоже удалось решить: дело оказалось в свойстве сортировочной таблицы, которое мы назвали cols (создавался массив, что-то вроде: t.cols[i] = document.createElement('col')). Так вот, слово cols оказалось у IE для чего-то зарезервировано, и после замены этого наименования на colg всё заработало везде.
Дальше возник вопрос, как раскрасить строку, чтобы не уничтожить фон столбцов? Напросилось очевидное решение: с помощью прозрачности. То есть никак не красить (или очень бледно), а добавить прозрачность. Тогда сквозь цвет выделенных строк будет просвечивать цвет столбцов. Ну, что-то такое приблизительно можно получить. Но прозрачность – отдельная песня, у каждого браузера своя. В некоторых опытах из-за фильтра сильно тормозила Опера, ну а уж IE тормозил железно и всегда. Поэтому от прозрачности пришлось отказаться.
Тогда (без использования opacity) фон строк полностью перекрывает фон столбцов. И тут уже ничего не придумаешь, кроме как красить каждую ячейку. Что в итоге и стало универсальным способом раскраски, позволяющем на пересечении крашеных строки и столбца задавать особое значение фона ячейки. В теории такой способ выглядит более медленным, но на практике разница в скорости между способами раскраски оказалась неизмеримо малой по сравнению с другими факторами (например, наличием той же прозрачности или способом создания сортировочного массива в IE).
Что нового в общении скрипта с пользователями
1. Предопределённая сортировка исходит от хозяина содержания таблицы, который может вообще не знать javascript. Но он генерирует HTML код. Мы должны дать понятную инструкцию именно для этой части: добавил что-то в HTML таблицы – и javascript что-то делает. Ясно, что это какой-то атрибут. Я не люблю использовать для таких целей всеми заезженный class. К счастью, у ячеек HTML таблицы есть никому не нужный атрибут axis, он вовсю используется в версиях Big Table Sorter'а.
2. Выбор столбцов для сравнения по содержанию строк. Всё то же самое, что и в первом пункте. Но "лишний" атрибут axis только один. И раз уж мы всё равно его используем, то почему бы и не отступить от жёстких правил (здесь: от авто-распознавания типа столбца) и не позволить автору таблицы явно указывать в каких-то случаях тип сортировки.
Всё вместе приводит к такому формату ячеек заголовка таблицы: <th axis='num:asc:alt'> – три вида значений, разделённых двоеточиями. Первое – тип столбца (str или num, легко добавить русскую и английскую даты). Второе – порядок предопределённой сортировки (asc или desc), если он отсутствует, то и не будет по этому столбцу сортировки "без спроса", сразу при открытии страницы. И третье – константа (только 'alt'), означающая, что столбец участвует в анализе содержания по строкам.
3. Следующее отступление от минимализма было сделано последним по времени, но оно очень простое: это добавление секундомера. В начале скрипта можно установить параметр show_log = true, и тогда в самом верху страницы будут выводиться миллисекунды, показывающие время некоторых операций: первоначальная загрузка DOM, подготовка таблиц, создание массива, сортировка, отрисовка строк в новом порядке.
4. Ещё один простой параметр – strip_tags = true, он говорит о том, что все HTML тэги из текстов, участвущих в сортировке, будут удалены (или нет).
5. Параметр axis_require = false вводит мягкий режим указания типов: если тип не указан, скрипт будет распознавать его автоматически, по алгоритму, описанному в начале статьи. Если указать axis_require = true, столбцы, у которых не указан тип сортировки, будут исключены из обработки (вообще не будут реагировать на щелчки мышью).
У столбцов с явно указанным типом алгоритм сортировки немного другой. Пример: если не указать тип у столбца со значениями вида "87$-93$", "137$-145$", то при создании массива часть после дефиса будет отброшена, а всё остальное превратиться в число, и строки, начинающиеся с 87~, будут выше строк со 137~. Если указать у такого столбца тип "число", для превращения в число будут использованы ВСЕ цифры строки, то есть получаться числа вида "8793", "137145", по которым сортировать уже совершенно бессмысленно. Если указать тип "строка", то 137 будет выше, чем 87, но значения соберутся более-менее кучно (примерно так же, как и без указания типа, но по другой схеме).
6. Параметр digit_arrow = true меняет в ячейках заголовка треугольные стрелки указания сортировки на квадратики с числами, обозначающими, каким по счёту был отсортирован столбец.
7. Ну, и наконец, два самых первых параметра (после init) – bg_cols = false, bg_cells = true – говорят о том, что столбцы на уровне элементов col подсвечиваться не будут, а будет раскрашиваться каждая ячейка таблицы (у каждого столбца в свой цвет). Эти параметры можно подключать одновременно.
8. Ещё более ранняя функциональность – восстановление первоначального вида таблицы. Дух минимализма запрещает рисовать для этого кнопку, обойдётесь щелчком мыши по любой ячейке заголовка с удержанной клавишей Ctrl.
9. А вот ещё сомнительная функциональность: пользователь (а не хозяин таблицы) может сам определять, какие столбцы должны участвовать в анализе содержания; для этого при сортировочном щелчке надо удерживать клавишу Shift или Alt.
Массив сортировки
При подготовке массива теперь к значениями не добавляется маленькая десятичная дробь; в массиве есть "колонка" индекса, она на втором месте, и массив просто сортируется весь целиком. Каждый элемент массива теперь является массивом и выглядит так: [значение, индекс, [HTMLRowElement]]. А поскольку "значение" всегда приводится к строке (как описано выше), дальше, при одинаковых значениях, сортировка автоматом происходит по второй "колонке".
Такое ловкое решение стало возможным благодаря тому, что при сортировке каждый раз создаётся новый массив. В Большом сортировщике массив создаётся в начале загрузки страницы один раз (данные типа кэшируются). Но тогда надо сортировать не просто командой sort, а специальной пользовательской функцией (которая будет выбирать элементы из сложного массива для сортировки). На скорости это мало сказывается, но зато отсутствие генерации отдельной функции позволяет уменьшить размер кода.
Я, конечно, не такой жлоб, чтобы вот так вот просто мучать пользователей медленным исполнением ради красоты кода скрипта. Просто в данном случае кэширование не играет решающей роли. Это проверено годами эксплуатации сортировщиков в разных условиях, после величины в 500-1000 строк, скорость сортировки таблицы решающим способом можно изменить только с помощью разбивки на страницы. Плюс необходимость фильтрации (на больших объёмах сортировка уже не спасает, не позволяет быстро находить данные). Именно в такой последовательности: 1) постраничный вывод больших объёмов, 2) фильтрация (поиск) данных, и только потом 3) кэширование – тогда оно хорошо помогает ускорять систему. Без первых двух пунктов кэширование (и специальные функции сортировки) – только лишнее запутывание кода.
Небольшая "мелко-кэширующая" хитрость применяется при отрисовке строк в новом порядке: сначала они добавляются в невидимый элемент tBody, который потом сразу, целиком заменяет "тело" видимой таблицы. Это, и ещё кое-какие извращения типа cloneNode добавлены в данной версии исключительно ради снижения тормозов IE (нормальным браузерам всё это по барабану, они сортируют объёмы в 1-2 тысячи строк с треском без всяких ухищрений).
Структура программы
Весь javascript код по-прежнему лежит в одном файле tabsort0.js (теперь размером 7.7 K), вспомогательные функции (например, для работы с className) в этом же файле. В начале Главной функции файла – переменные для настроек (вроде show_log). Схема отображения – в файле tabsort0.css.
Одно из свойств хорошего поведения таблицы – подсветка строк при наведении мыши (особенно для широкой таблицы). Связанные с этой функциональностью файлы CSS сделаны отдельно для IE и для обычных браузеров (ie.css, ie_free.css). Эти файлы подключаются скриптом динамически, после анализа свойства userAgent. В ie.css по умолчанию всё закомментировано. Дело в том, что в длинных таблицах (1000 строк) использование подсветки строк страшно тормозит уродца. Поэтому раскомментировать будете на свой страх и риск.
В файле ie_free.css закомментирована прозрачность. Её надо добавлять осторожно, внимательно изучать, как она работает в разных ФФ и Операх.
Стрелки, отображающие направление сортировки в заголовках (треугольные или с числами), хранятся в папке img в виде картинок gif. На медленных соединениях с интернетом они могут плохо прорисовываться, поэтому их надо подгружать заранее: создать невидимый HTML контейнер и поместить туда все картинки. В данной версии это делает сам скрипт.
Подключение и выводы
Подключать систему к HTML файлам с таблицами по-прежнему просто. Надо 1) распаковать файлы дистрибутива SimpleTableSorter0.03.zip в папку HTML документов; 2) добавить сортируемым HTML таблицам атрибут "class='sortable'"; 3) дописать в HTML документ (в секцию head) две строки:
Можно ещё добавить к ячейкам заголовка таблицы атрибуты axis с явно указанным типом данных и другими метками, как описано в разделе «Что нового для пользователей».
Можно добавлять к данному сортировщику какие угодно функции, но без функции постраничного вывода они будут бесполезны на объёмах больше 500-1000 строк. Не из-за алгоритмов сортировки или кэширования, а потому что природу не обманешь: браузер просто не успевает отрисовывать новую таблицу, и всё будет выглядеть плохо (будто таблица сортируется медленно).
Вот пример – сравнение скорости сортировки (в Firefox) двух таблиц, в 450 строк и в 1000.
http://ir2.ru/static/sort0.03/table400.htm:
buildSarr (2, num:desc:alt, 448 str): 29; sort: 1; draw: 54;
http://ir2.ru/static/sort0.03/table1000.htm:
buildSarr (2, num:desc:alt, 1022 str): 63; sort: 3; draw: 121
У таблицы в 1000 строк общее время работы скрипта (188 мс) примерно вдвое больше, чем у маленькой таблицы (84 мс). Взглядом эту разницу (между 80 и 180 мс) заметить невозможно. Однако большая таблица после щелчка по заголовку переходит в новое состояние заметно медленней. Скрипт тут ни при чём, просто браузер дольше выводит на экран длинную страницу. Поэтому вся более сложная работа с таблицами (в Большом сортировщике) начинается с укорачивания большой страницы (деления её на более маленькие).
Комментарии
супруги Кошутины
07.05.2015 00:57:01
да, ипричё1м тут joomla? тытоджывладимер, что про АЯКС? нада: ВСЁ – код отправки аякса, код html. А то я нииграю.
супруги Кошутины
07.05.2015 00:52:47
эээ... не понил, что зассы лка? лучше напяшите реальны код
Владимир
28.04.2015 06:09:41
Здравствуйте, скрипт классный. Такой вопрос: столкнулся с такой проблемой на joomla 2.5 при вставке таблица в материал так ссылка – материал = таблица работает, а если ссылка – ссылка – материал = не работает. Не подскажите, что нужно сделать чтоб заработало. Пробывал Разместить на одной странице несколько таблиц = не работает. Первую сортирует, и все.
Владимир
09.02.2015 12:00:15
Сортировка таблицы просто классная, но не работает в случае получения таблицы через АЯКС