Первое, что нужно сделать с большим HTML-списком (или таблицей) - перед загрузкой страницы запретить отображение этого большого объекта с помощью инструкции CSS display:none
Как с очень высокой скоростью найти слово в большой таблице?
В предыдущей статье мы показали, как два уровня (или два приёма) javascript-кэширования могут увеличить скорость поиска по списку из 400 элементов в десятки раз. Там были важны три момента:
- Вести поиск не по HTML-элементам, а по javascript-массиву текстов, извлечённых из элементов.
- Отображать найденные элементы не по одному, а накопить сначала в невидимом контейнере вне страницы, а потом отобразить сразу весь контейнер.
- Обрабатывать только полезные (с найденным тектом) HTML-элементы (к ненужным не обращаться даже с вопросом "который час").
И как всё это поможет работать с таблицей в 14000 строк?
Никак. Вернее, вы не узнаете, как это может помочь, потому что у вас не хватит терпения дождаться загрузки такой таблицы. Может, конечно, и хватит на один раз, но ведь это будет повторяться с каждой операцией (поиска или сортировки): см. latrus-full.htm.
Первая операция, которую нужно делать с большим HTML-списком (или таблицей) – перед загрузкой страницы назначить правило, запрещающее отображать этот большой объект. Наши программы фильтрации и сортировки обрабатывают все таблицы с класснэймом sortable. Поэтому для больших таблиц достаточно вписать в файл скрипта (с учётом того, что скрипт подключён через head) правило:
Можно и просто записать это правило в файл стилей (CSS). Тогда отображение страницы будет происходить намного быстрее (ср. latrus-null.htm). Потому что зарузка страницы (распознавание браузером HTML-кода и создание из него дерева DOM) и вывод её содержимого на экран – это всё-таки разные процессы.
Что показать пользователю
Элемент со свойством display:none отображается, конечно, быстрее. Но если у нас на странице всего один такой основной элемент, то надо решить, что же будет видеть после начальной загрузки пользователь. Ответ достаточно тривиален – первую страницу текста большого элемента. То есть то же самое, что показывает браузер, Блокнот, swriter или любая другая программа, работающая с текстом – программы ведь показывают только фрагмент, первую страницу, а увидеть остальное можно, листая страницы.
А вот решение задачи не очень тривиально. Нужно назначить произвольный размер страницы (количество отображаемых строк) посчитать общее количество строк в списке (таблице), определить количество страниц. Да, и ещё надо как-то отдельно посчитать полезные строки (с найденным текстом) – мы ведь ради поиска всё это затеяли.
Ну, вся эта техническая лабуда нас сейчас не интересует, достаточно знать, что решение существует (и мы его будем счас использовать).
Третий уровень кэширования
Мало того, что таблица изначально, перед загрузкой делается невидимой. Перед формированием javascript-массива (для сортировки и поиска данных) она вообще «выдирается» из структуры DOM, самым натуральным образом – в функции makeSortArr(), приблизительно в строке 521 файла tabsort3.js:
Ну, это, конечно, не removeChild, но результат тот же самый – главная часть таблицы tbody удаляется из таблицы и прикрепляется к вновь созданному элементу table, который в дальнейшей работе не добавляется к DOM документа, а так и остаётся висеть «в нигде», в «тени». Благодаря этому хитрому ноу-хау скорость подготовки сортировочного массива (и последующих обращений к нему в процессе поиска-сортировки) возрастает в несколько раз.
Результат можно протестировать на странице latrus.htm – попробуйте ввести слово «vulgo» в поле ввода под заголовком таблицы «Слово». Первая буква ищется с некоторой задержкой, а дальше все результаты отображаются практически одновременно с вводом букв – ещё один элемент ускорения: принцип «поиска в найденном», а не каждый раз во всём массиве, как было при фильтрации простого списка на странице listru3.htm.
Последний удар – создание javascript-индексов для таблицы
Это четвёртый, последний важный момент создания промежуточных хранилищ для данных (кэширование при работе с базой данных можно назвать и так). Фильтрация по заголовочным полям ввода всегда будет тормозить при вводе первой буквы (или при вставке из буфера целого слова). Природу не обманешь: нельзя потратить на поиск значения меньше времени, чем требуется для просмотра в цикле массива из 14000 элементов (и сравнения каждого элемента массива с искомой строкой).
Но, оказывается, можно всё-таки ещё ускорить поиск – не обманывая природу, а постигая другие её уровни. Если поставить галочку во флажке is_dict (в ряду флажков вверху страницы latrus.htm) и перегрузить страницу, над панелью навигации по страницам появится ещё одна строка – панель поиска:
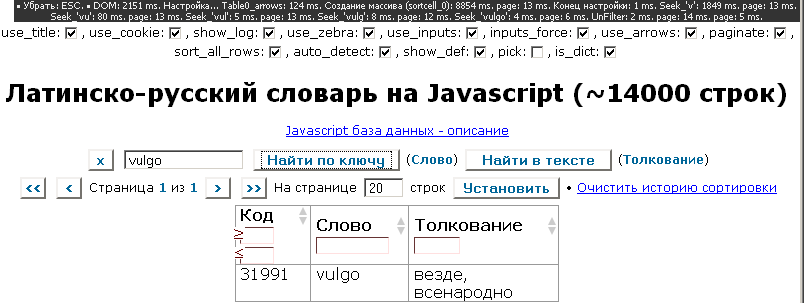
Попробуйте ввести то же слово «vulgo» в окно панели поиска и нажать кнопку Найти по ключу. И это ещё не предел! Гораздо интереснее ввести в панель поиска не целое слово, а часть (например, «vulg» – результат будет ещё более впечатляющий: скорость поиска та же, а слова выдаются целой кучей.
Для того чтобы всё это работало, пришлось вдобавок к обычному сортировочному массиву создать ещё два «индексных» объекта:
- Первый индексный объект sarr (файл tabsort3.js) очень прост и достаточно очевиден: он состоит из элементов вида «Свойство»:«Значение», где в позицию «Свойство» записываются тексты из колонки таблицы с заданным атрибутом axis='idx', а «Значение» является ссылкой на строку таблицы (HTMLRowElement). Таким образом, находить строки таблицы можно, просто изпользуя выражения вида sarr["vulgo"] (т.е. в цикле искать ничего не надо!).
- Второй индексный объект (farr) сложнее. Точнее, по структуре он проще – это массив, числовые индексы которого как-то связаны со строками таблицы. Но как именно, сообразить очень трудно. Там как-то буквы превращаются в цифры, а потом всё это становится индексом массива. А потом, при поиске (функция seek() в файле tabsort3.js), опять буквы искомого слова превращаются в цифры, и полученное число сравнивается с каждым числом – индексом массива farr.
Это всё. В этой статье было рассказано о двух моментах, ускоряющих работу javascript-сценариев с большими (>10000 строк) HTML-таблицами:
- Формировать кэширующие массивы и отображаемые браузером фрагменты данных нужно из элемента, не имеющего своего места в DOM (созданного createElement, но не вставленного на страницу с помощью insertBefore или appendChild).
- Для быстрого нахождения значений можно создавать javascript-индексы HTML-данных, подобные индексам обычных БД.
Эти простые правила позволяют нашему скрипту Big Table Sorter работать с таблицей в 14000 строк быстрее, чем, например, jquery.tablesorter работает с таблицами в 500 строк.
Комментарии
Elena
29.03.2014 09:30:57
Подскажите пожалуйста как убрать вверху страницы строки с галочками. Чтоб они вообще не отображались. Спасибо.
лесник
23.10.2012 19:00:23
Максим,
можно сделать в принципе всё. Но откуда будет браться ссылка со значением, по которому надо будет фильтровать таблицу? Тут, скорее, логично сделать выпадающий список для каждого столбца таблицы (если там много повторяющихся значений).
Поля для поиска генерируются в файле tabtools.js, там же создаётся глобальная переменная global, и поля добавляются к ней как свойства. Т.е. получить доступ к полям поиска можно как-то так: global.inputs_el (точнее надо смотреть в коде).
Максим
12.10.2012 00:43:25
Хотел использовать вот такую функцию var line=" параметр"; var i=0; function m_line() { if(i++<line.length) { document.forms[0].elements[0].value=line; } else {document.forms[0].elements[0].value=" "; i=0;}; } , но не придумал как получить доступ к полям фильтрации.
Максим
11.10.2012 23:43:19
Здравствуйте, подскажите, пожалуйста, с помощью Вашего скрипта http://ir2.ru/static/BigTableSorter.zip сделать так, чтобы при щелчке по ссылке происходила фильтрация таблицы по определенному значению?
лесник
20.01.2011 17:26:17
Можно. Вот все файлы, используемые в статье, в одном архиве: http://ir2.ru/static/biglist2_files.zip
Евгений
20.01.2011 06:17:35
а чо примеры отдельным файлом нельзя включить?