Веб/2 или "веб пополам" - нечто противоположное Веб 2.0 ("веб-два-ноль"). Один из главных принципов Веб/2 - пользователь сам определяет объём открываемой страницы и размер её видимой части (параметры постраничного вывода).
Веб/2: сайты нового поколения
Предыстория
Чтобы дать определение новому понятию «Полувеб», надо вспомнить сначала, что такое «веб 2.0». О нём много пишут; как всегда, лучше всего в Википедии. С содержательной стороны – это сервисы, заставляющие пользователей давать больше информации (и больше информации хранить на удалённых серверах в Интернете, а не у себя на компьютере). Это тема отдельной статьи, поэтому особо вдаваться не будем, указав лишь на одну особенность веб 2.0: интернет-сервисы используют любую возможность, чтобы залезть без мыла в самые удалённые уголки вашего компьютера; наиболее крутые сервисы устроены ещё хитрее: например, вебвизор не сам залезает на ПК посетителей, а вы сначала устанавливаете его часть на своём сайте, а уже оттуда он начинает следить за пользователями вашего сайта – это уже получается не 2.0, а 3.0, веб a trois!
Но это содержательная (или политическая) сторона, а нас, как всегда, больше интересует внутреннее устройство, техническая сторона работы того или иного сайта. С этой, технической стороны, веб 2.0 можно характиризовать такой фразой, как «больше интерактивности», то есть как бы веб умноженный на два, вдвое вебистее обычного.
Больше интерактивности – значит больше HTTP-запросов. Например, открываете вы письмо на mail.ru. Раньше было как: щёлкнул по ссылке, открылась страница с письмом. Один запрос, один ответ сервера (ну, основной ответ с текстом, не считая картинок, конечно). А теперь, после открытия страницы с письмом на mail.ru (со всякими служебными текстами), javascript посылает ещё один (как минимум) запрос, по которому браузер отдельно получает текст письма. И если письмо по объёму больше служебных текстов, такая схема нерациональна, один запрос будет получен быстрее, чем два.
На mail.ru такая схема всё же необходима – кроме всего прочего, получение текстов писем фоновыми запросами обеспечивает ещё и безопасность: если вы разлогинетесь и отойдёте от компьютера, другой человек (например, промышленный шпион) может подойти, включить автономный режим в браузере и, щёлкая по истории (Журналу), просмотреть все ваши предыдущие страницы. Вот только они будут без текстов писем, потому что в автономом режиме запросы (даже фоновые) работать не будут, и браузер ничего не сможет получить с сервера (а без автономного режима потребуется банальная авторизация).
Другой пример – списки подсказок в поисковых системах (ПС) при вводе букв в поле поиска. Вводите одну букву – список подсказок меняется. Потому что с вводом каждой буквы (и даже чаще) браузер отправляет на сервер ПС новый фоновый запрос, который и меняет список подсказок. Или, например, вы вводите имя пользователя в форму авторизации/регистрации на сайте объявлений irkutsk.ir2.ru: если буквы покраснели, значит, такой пользователь уже есть, нужно вводить корректный пароль. Как браузер узнаёт о том, что в базе данных пользователей на сервере есть такой пользователь? Да всё тем же фоновым HTTP-запросом: страница не перегружается, а информация получена.
Или, например, вы прокрутили страницу – на сервер отправился запрос, щёлкнули по кнопке – запрос, нажали на клавишу – запрос, просто шевельнули мышкой – запрос... Так работают шпионские системы типа «вебвизор». Да. Поэтому лучше всего шариться по современному Интернету с отключенным javascript (если система, например, авторизации на каком-то сайте прямо не требует его включения – на нашем сайте авторизация без javascript невозможна).
Какой веб лучше
Итак, веб 2.0 назван так в знак усиления своих качеств: он больше веб, чем обычный, вдвое больше (или в квадрате), более вебистый и крутой. Но не более правильный с точки зрения технологической основы Интернта – HTTP-протокола. Потому что HTTP-протокол изначально построен так, чтобы минимизировать количество запросов к серверу, оптимально распределять информацию между сервером и клиентом. А веб 2.0, пользуясь растущими техническими возможностями «железа», стремится перетянуть все одеяла на свои серверы. История совершает виток. Сначала путь развития компьютеров был другим:
– Вспомни, почему фирма «Microsoft» так старалась вытеснить с рынка интернет-браузер «Netscape»?
– В то время никто не знал, как будут эволюционировать компьютеры, – сказал я. – Было две концепции развития. По одной, вся личная информация пользователя должна была храниться на хард-диске. А по другой, компьютер превращался в простое устройство для связи с сетью, а информация хранилась в сети. Пользователь подключался к линии, вводил пароль и получал доступ к своей ячейке. Если бы победила эта концепция, тогда монополистом на рынке оказался бы не «Microsoft», а «Netscape».
(Виктор Пелевин, «Empire V»)
Теперь как раз всё происходит по второму варианту: пользователи подключаются к своим ячейкам, вводят пароли, и работают с информацией, реально находящейся чёрт знает где. Только монополистом стал не Netscape, а Google (опять мы съехали на политику).
Использование фоновых запросов (так называемый AJAX), без которых не был бы возможен веб 2.0, – само по себе неплохое средство. Это инструмент, который может приносить пользу в умелых руках. Пользу в соответствии с духом HTTP-протокола (который прямо ничего не говорит о фоновых запросах): если надо обновить небольшую часть страницы, фоновый запрос более правильно позволит распределить нагрузку между сервером и клиентом.
Но бывает обратная ситуация, когда рациональнее сразу получить с сервера большой объём данных, и потом работать с ними только в браузере, а к серверу больше не обращаться.
Полувеб или Веб/2: возвращаемся к основе
Как должен называться шаг в другую сторону – не ускорение клиент-серверного обмена, а снижение его частоты? Веб, который не больше единицы, а меньше? Веб 0.5? Ну, что-то в этом роде. Пусть будет Веб/2.
Речь идёт о ситуации, описанной в статье HTML база данных лучше, чем Excel – когда есть данные, есть клиент (браузер или hh под Windows – для чтения .chm), но нет веб-сервера. Формат chm – очень мощная замена веб-серверу, с встроенным полнотекстовым поиском и возможностью локально просматривать целые веб-сайты. Часто используется для работы с документацией (например, php_manual_ru.chm), для работы со словарями (например, толковым – http://infodisk.info/books/ozhegov.chm).
Эмуляция локальных баз данных – не единственное применение найденных нами решений, их можно также использовать для идеального распределения нагрузки в работе веб-сайтов. Возьмём тот же справочник Ильи Кантора javascript.ru/manual: одна маленькая страница об объекте String, а каждая функция (метод этого объекта) открывается уже на новой странице. «Это страшно невыгодно», как говаривал Скрягинс Спрутсу: для одной страницы с 5-10 КБ полезного текста, на javascript.ru используется 100-200 КБ «файлов обеспечения». То есть большие накладные расходы.
Обратный пример: в справочнике Юрия Лукача (wdh.suncloud.ru/contents.htm) совмещается описание и объекта String, и его методов на одной странице – тоже ничего хорошего. То есть для сервера это хорошо (нагрузка меньше), а искать на огромной странице нужное место пользователю труднее.
Решение как раз и содержится в нашей модели ВЕБ/2: страница, отдаваемая сервером, должна быть (достаточно) большой, но пользователь должен видеть её «как на сервере» – оглавление со ссылками на фрагменты страницы. Так можно не только описание объекта String сделать удобным, но и достаточно большие документы – например, Конституцию России (116 КБ):

Или даже целый Гражданский Кодекс (1.7 МБ).
Это Первая форма нашего Веб/2 – электронный документ. Вторая форма – список с постраничным выводом. Постраничный вывод используется часто при поиске информации: на ПС (Яндекс, Гугл), в справочниках телефонов, на трекерах (torrents.ru или rutracker.org)... Используется, как правило, очень неоптимально. ПС выдают информацию какими-то муравьиными дозами (по 10 штук), и каждую новую страницу надо загружать (часто с заметными задержками) а если увеличить размер страницы, например, до 50, будет неудобно искать глазами в большом списке.
То же на трекере: почему размер страницы с искомыми фильмами там 50, а не 150 (или не 500)? Ясно, что таблица в 500 строк на трекере будет «тяжёлой». Но ведь на торрентс никто не лазит без неограниченного трафика, а одна страница в 500 строк будет как угодно загружаться намного быстрее, чем 10 страниц по 50 – из-за накладных расходов. То же и на Яндексе, и на любом другом сайте, выдающем результаты поиска в большом объёме.
Вот идеальное решение нашего Веб/2 для подобных случаев – страница телефонного справочника http://allo-irkutsk.ru/Строительство/:
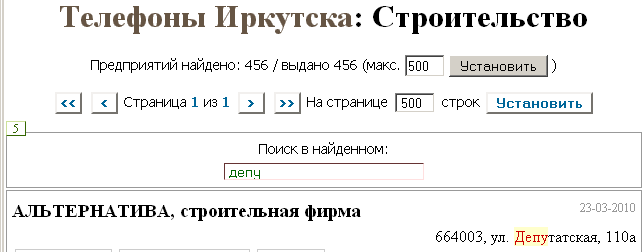
Страница размером 350 КБ (полезного текста 100 КБ); пользователю выдано 456 результатов поиска. Это не очень большой размер, на современных сайтах страницы в 500 КБ (и с 5 КБ полезного текста) стали достаточно частым явлением. Но если пользователю этого покажется много (или наоборот мало), можно свободно выбрать любой другой размер страницы (100, 700, 1000...).
Видимая часть страницы (по умолчанию 20 результатов) тоже свободно регулируется по желанию пользователя. То есть пользователь всё определяет сам: и «внешние», и «внутренние» параметры страницы – это первый принцип Второй формы Веб/2 (списка с постраничным выводом).
Второй принцип – быстрый (быстрее, чем на веб-сервере!) доступ к информации, фильтрация, поиск и сортировка данных. Нашли 500 результатов – потом через поле «Поиск в найденном» мгновенно выбираем из 500 всего 5, вводя в поле поиска буквы. Ничто не мешает применить эту технологию и в Первой форме Веб/2 – электронном документе; достаточно определить для этого минимальный фрагмент, который должен отображаться при нахождении в нём нужных символов – это может быть абзац текста или, например, статья закона.
В результате всем хорошо: пользователь находит всё быстрее (все операции после загрузки страницы практически мгновенны), а сервер, отдав один раз большую страницу, вообще больше в работе не участвует.
Какой javascript в последнем примере всё это выполняет? Смотрите исходный код страницы – четыре файла (common.js, firms.js, tabtools1.js, tabsort1a.js), общий объём 17 КБ.
Комментарии
лесник
31.12.2011 01:09:09
Фу, блин. А сейчас что, есть свобода? Любая власть всегда будет защищать себя руками и зубами. Свобода всегда будет у того, кому на__ть на власть. А кто хочет сменить власть, того будут гнобить. Это просто.
Роман
20.12.2011 02:00:11
"Было две концепции развития. По одной, вся личная информация пользователя должна была храниться на хард-диске. А по другой, компьютер превращался в простое устройство для связи с сетью, а информация хранилась в сети. " Второй вариант – угроза для свободы информации. Легко ввести цензуру и следить за всеми. Тогда не будет свободы в сети, и будет сеть, как ТВ, управляться из центра. POLICE STATE: Cloud Computing to Destroy Internet Freedom ... http://www.youtube.com/watch?v=eEEwmpScMp4